bert hubert 🇺🇦🇪🇺🇺🇦
bert_hubert@eupolicy.social
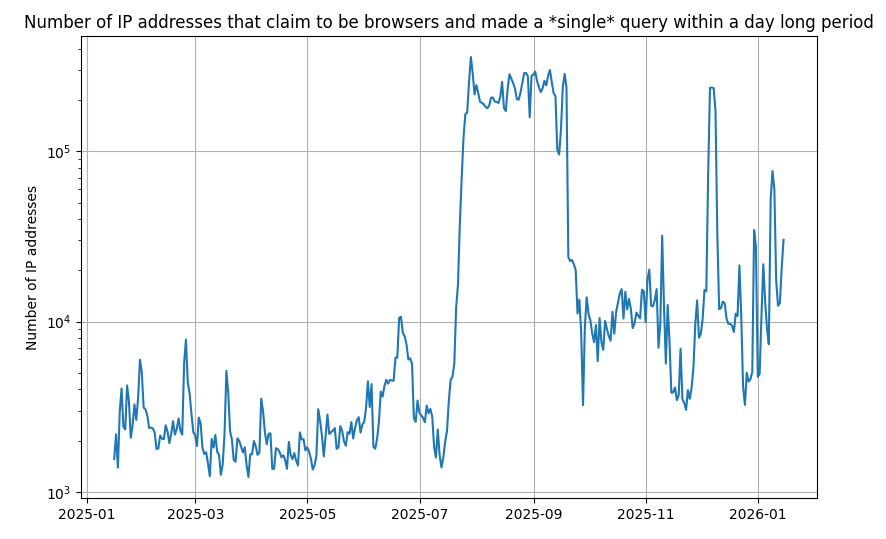
So after the @lwn post on being hammered by scrapers today, I ran an analysis on what I thought was a recent phenomenon: a query from what tries to pass as a browser from an IP address that does exactly *1* query in a 24 hour period. You can't filter an IP address that makes just one visit. Turns out this happens a lot, sometimes 250k unique single use addresses/day!
 3
3
 0
0
 0
0
@bert_hubert @lwn
Is there any pattern to the addresses?
I heard some rogue crawlers use cheaply made "free to play" mobile game apps that mainly serve as bot platform to query from hard to block residential ip space.
1
0
0
bert hubert 🇺🇦🇪🇺🇺🇦
bert_hubert@eupolicy.social 0
0
0
0
0
0
Jonathan Corbet
corbetSomething has to be done about this, but I sure don't know what. They are using other people's devices, so they don't really care about burning some CPU time on Anubis challenges - and they have evidently learned to do that.
Sometimes I think we need to just toss the net and start over.
0
1
5
Solarpunk Davy
SolarDavy@climatejustice.social
@bert_hubert maybe a lot of self-hosted rss readers? /j
1
0
0
bert hubert 🇺🇦🇪🇺🇺🇦
bert_hubert@eupolicy.social@SolarDavy nope, nothing like that. They also check far more than once a day!
1
0
0
Solarpunk Davy
SolarDavy@climatejustice.social@bert_hubert yeah, it was a very bad joke (I added the joke modifier).
I mean, self-hosted rss is soo niche, I would love it if it wasn't 😅
1
0
0
bert hubert 🇺🇦🇪🇺🇺🇦
bert_hubert@eupolicy.social@SolarDavy it is not as niche as you might think! I get a shitload of RSS queries!
0
0
0
Solarpunk Davy
SolarDavy@climatejustice.social@jwildeboer @bert_hubert do you know if they're from self-hosted rss clients (for example miniflux)? Or more stuff like Feedly?
0
0
0