Rob Ricci
ricci@discuss.systems
Hey! Let's talk about #SSH and #security!
If you've ever looked at SSH server logs you know what I'm about to say: Any SSH server connected to the public Internet is getting bombarded by constant attempts to log in. Not just a few of them. A *lot* of them. Sometimes even dozens per second. And this problem is not going away; it is, in fact, getting worse. And attackers' behavior is changing.
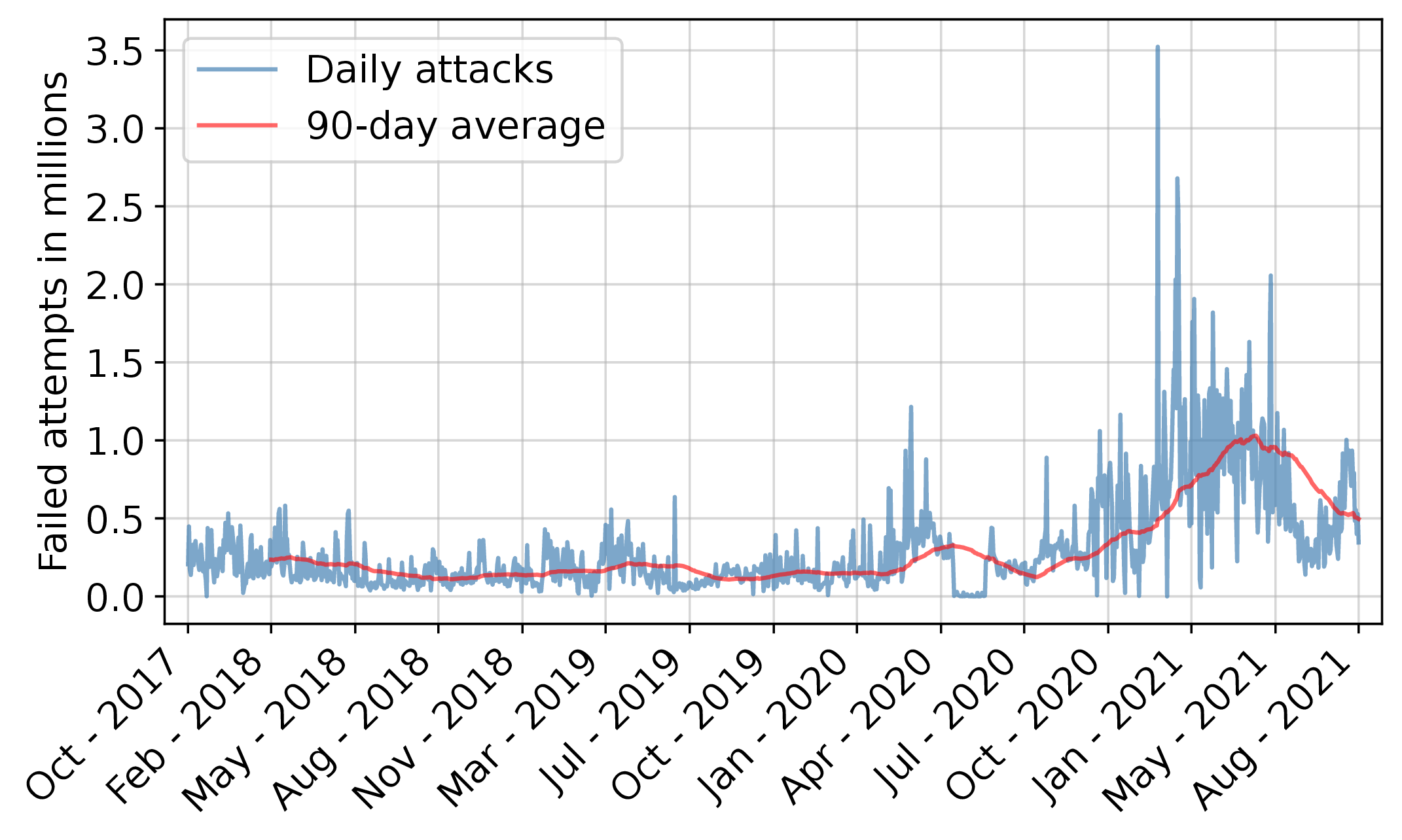
The graph attached to this post shows the number of attempted SSH logins per day to one of @cloudlab s clusters over a four-year period. It peaks at about 3.4 million login attempts per day.
This is part of a study we did on our production system, using logs of more than 640 million login attempts, covering more than 1,500 hosts on our side and observing more than 840 thousand incoming IP addresses.
A paper presenting our analysis and a new, highly effective means to block SSH brute force attacks ("Where The Wild Things Are: Brute-Force SSH Attacks In The Wild And How To Stop Them") will be presented next week at #NSDI24 by @sachindhke . The full paper is at https://www.flux.utah.edu/paper/singh-nsdi24
Let's dive in. 🧵
 5
5
 21
21
 0
0
Rob Ricci
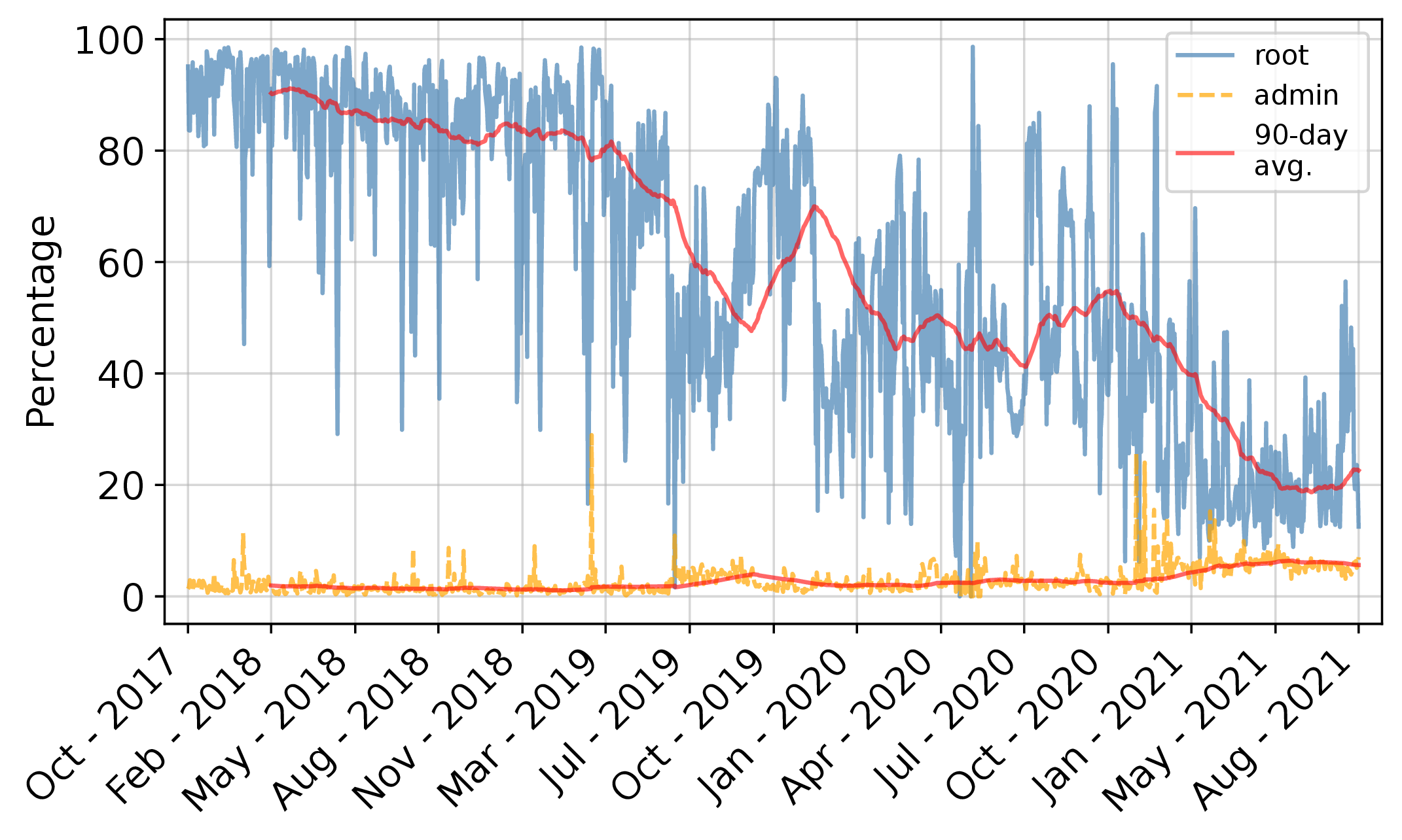
ricci@discuss.systemsFirst things first: everyone "knows" that most brute force attacks are against the "root" account, right? This is certainly what earlier studies have found.
As it turns out, this used to be true, but it's not anymore. This graph shows that the fraction of brute force attacks using the username root was nearly 100% back in 2017, but it's been falling - by mid-2021, only around 20% off the attacks we saw were against root.
So, why? Well, we don't have a hotline to the attackers, but we have an educated guess from our own data and from many others' reporting: a lot of the usernames we see correspond to default usernames for #network #routers, specific #Linux distributions, specific server software, and #IoT devices. Basically, as we connect ever more stuff to the Internet (and generally try to protect the "root" account), attackers seem to be diversifying the accounts they are going after.
(There's a table of the top 100 usernames in the paper.)
 2
0
0
2
0
0
Rob Ricci
ricci@discuss.systemsHow do attackers pick their targets? In a word, randomly.
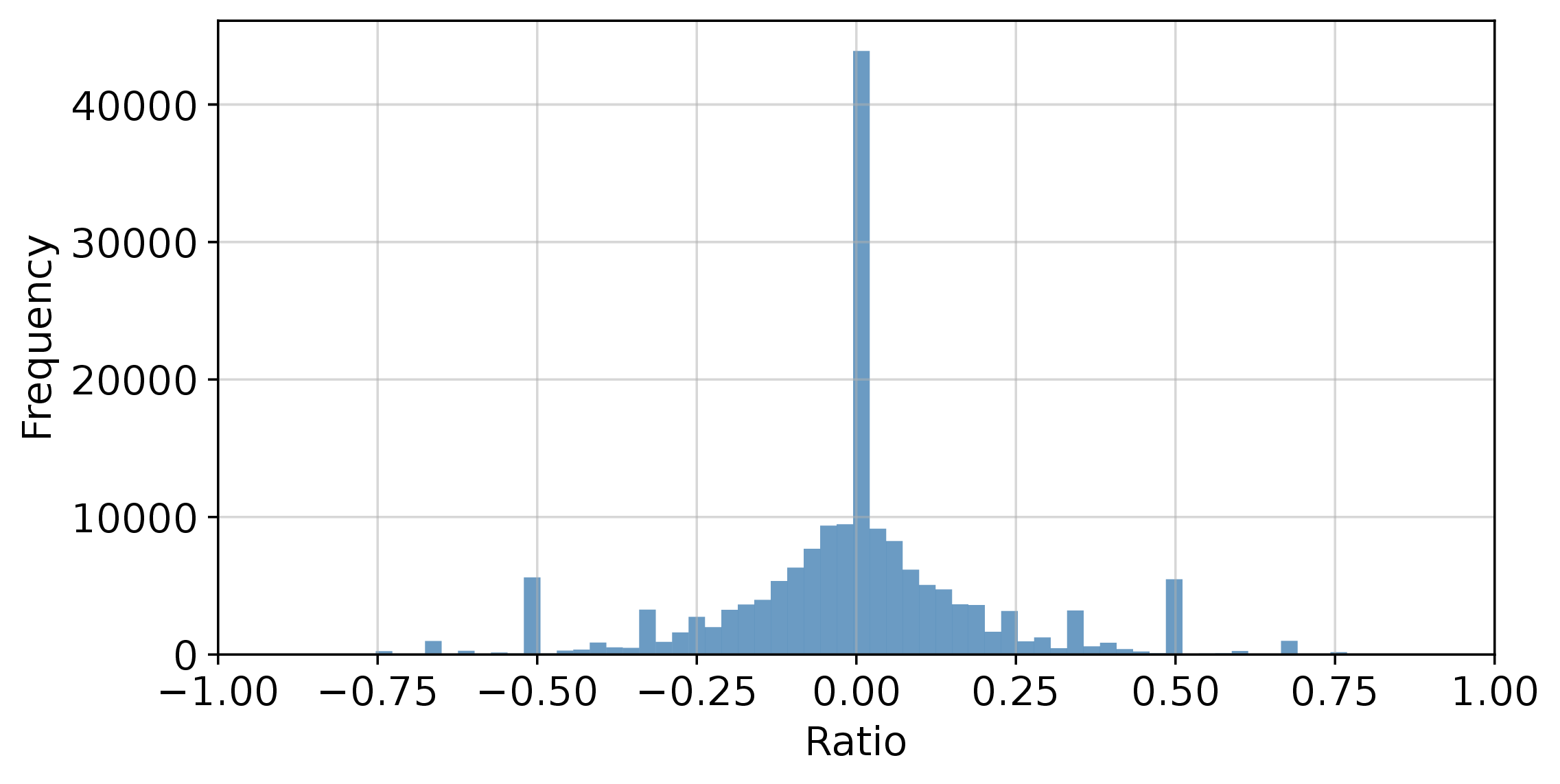
This graph shows what we call "sequence bias" - if an attacking IP address moves from lower-numbered target IP addresses to larger ones, we assign it a sequence bias of 1; if it goes from larger to smaller, we assign it a bias of -1. As you can see in this graph, most of them have a sequence bias of around 0, meaning that once we see an attack, the next target is equally likely to be either higher or lower.
Basically, this means that most attackers are scanning the IPv4 address space at random.
 1
0
0
1
0
0
Rob Ricci
ricci@discuss.systemsOK, so what can we do about all these SSH brute force attacks?
We have a plan - actually, not just a plan, we run this in production on one of the @cloudlab clusters.
Let's start with this observation: if attackers are using a broad set of usernames, then we can use these username sets as a sort of signature. About half of attacking IP addresses only try one username, but that also means that about half are trying more than one - in fact some individual IP addresses tried more than 10,000 usernames!
What we do is this: we find *sets* of usernames that are used by *more than one* attacking IP address (actually it's a bit more complicated that this, details in the paper). This gives us "dictionaries" of usernames that are *only* used by attackers, and not any of our real users. We collect these dictionaries from the logfiles of a bunch of SSH servers, and combine them to form a Username Block List (UBL).
Now, all we have to do is: as soon as we see an IP address try a username from this UBL, we block it. That simple. We call this Dictionary Based Blocking (DBB).
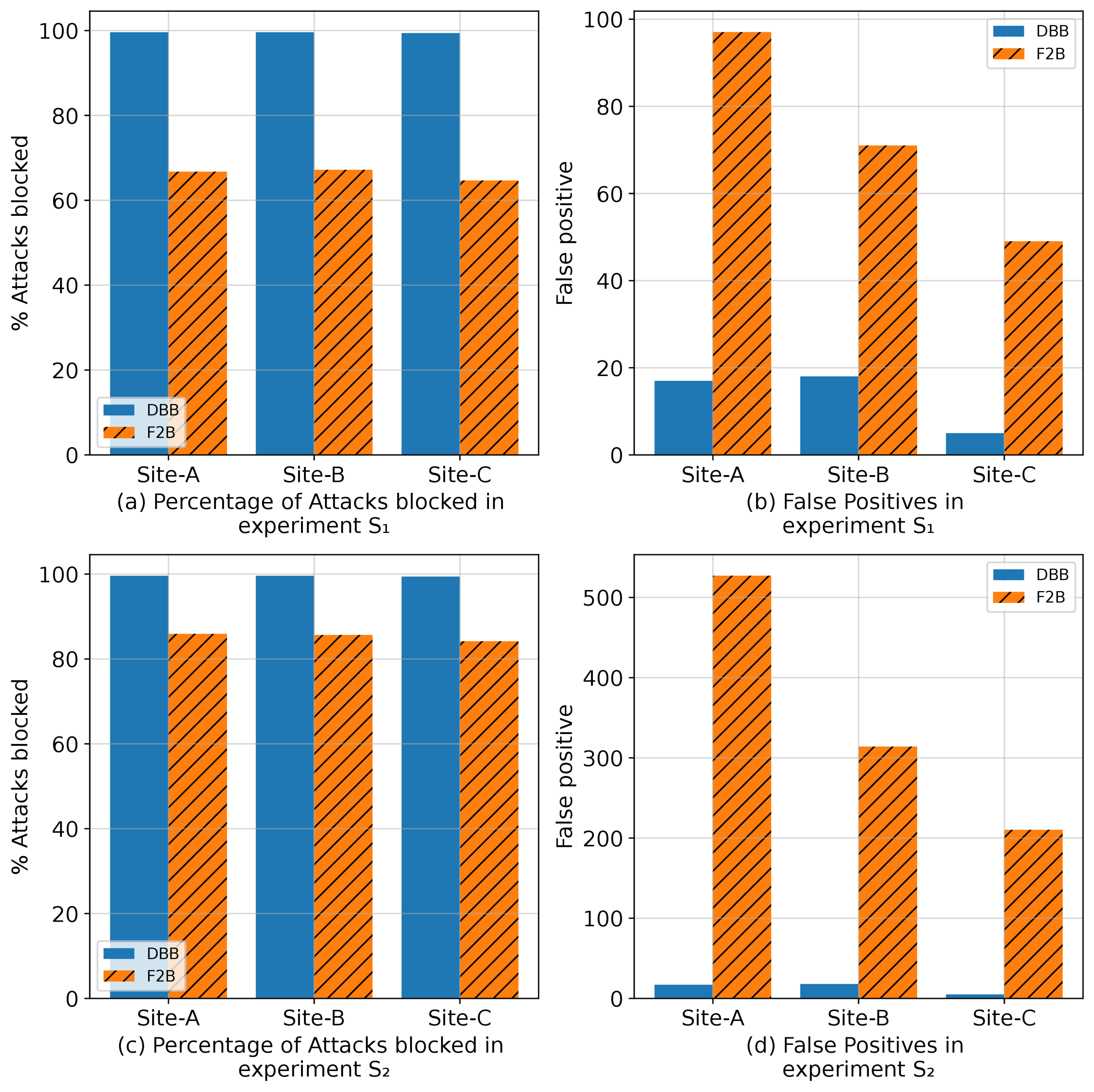
How well does this work? We used logs from our clusters containing a total of 213 million login attempts, and it blocked *99.5%* of all attempts, generating a false positives (accidentally locking out a real user) at a rate of just one about every five days.
But what about #fail2ban, you might ask? That's another method people use to block attacks against SSH (and other services) by locking out addresses that fail to log in more than X times in Y minutes. Well, with it's default settings, it only blocks about 66% of attacks, and it generates more than 5x as many false positives (graph attached). As it turns out, there is *no* way to tune fail2ban to get DBB's accuracy without a false positive rate that's orders of magnitude higher.
I said we run this in production - how well does that work? We run it on one of of CloudLab clusters that already had a firewall - subscribing to popular blocklists and running something very much like fail2ban. It's catching four-fifths of the attacks that were not already getting caught by these measures, and so far it hasn't caused a single false positive.
 1
2
0
1
2
0
Rob Ricci
ricci@discuss.systemsThere's a *lot* more in the paper - we analyze a bunch of different aspects of attacker behavior, and show that DBB is easy to collect data for and hard to evade. We've been working on this paper for years, and are quite proud of it.
You can read the paper right now at https://www.flux.utah.edu/paper/singh-nsdi24 - if you'll be at #NSDI24, you can come see the talk on Thursday, April 18th or ask @sachindhke or myself questions about it all week.
There are a lot of wild things out there - stay safe!
/ 🧵
1
0
1
Serge from Babka
serge@babka.socialThis bit about the usernames is interesting.
Assuming the system is being used as a bastion/jump host, then are we still secure in key exchange, or should we start thinking about usernames the way we do about API bearer tokens, assigning long, randomly generated strings for the username (since we're reasonably safe on the key)?
Or at that point, do we just move onto another technology like VPNs (eg Wireguard)?
1
0
0
Rob Ricci
ricci@discuss.systems@serge Excellent question. My take is that if you are taking your SSH security seriously enough to be thinking about this, the answer is no. As long as you have locked down your logins to disable password auth and have disabled root logins, that's going to stop brute force attacks. (I will note that we're focusing in this paper on brute-force attacks and and what I'm saying is probably less applicable to targeted attacks.)
The real danger is devices that have default passwords and/or when users set easy to guess passwords on well-known accounts. As an example, one of usernames that shows up a lot in our dataset is 'pi', probably due to the fact that until painfully recently, that account had a well-known default password in Raspberry Pi OS / Raspbian.
That said, we did find that through spraying of lots of common personal names, attackers did manage to guess a non-trivial number of our users' actual usernames. But so long as you require your users to use keypairs, they're safe from password guessers.
1
0
0
Josh Triplett
josh@joshtriplett.org
1
0
0
Rob Ricci
ricci@discuss.systems@vathpela @serge We didn't write about this in the paper, but part of the reason I wanted to look at the random vs. sequential scanning thing is that back in prehistoric times, one of the practices people adopted was to have a 'tarpit' early in their IP space that would accept the connections then just hold on to them as long as possible to try to slow the attackers down. Our finding about random scanning suggests that this is not - currently - something that helps protect your own IP space, since attackers don't start from the bottom of your IP space.
My *guess* is that most of them are completely oblivious about blocks, failures, etc. - they are just trying to make as many connections as they can as quick as they can and are not being very careful about spending much effort avoiding hosts that are not fruitful
1
0
0
Rob Ricci
ricci@discuss.systemsExcellent question. To some extent, yes, there are fairly large efforts to shut down sources of network abuse. They come in a lot of different forms.
There are IP address blocklists that are maintained by a bunch of different professional and volunteer organizations. These are only effective if you actually use them, and there are reasons not to - for example, getting off them can be hard (because of course bad actors try to get off of them) but this means they catch a lot of 'innocent' addresses too.
Then there are security researchers and law enforcement that try to track down the actors themselves - follow @briankrebs for this kind of thing. These are often fairly long, intensive efforts, that have big payoffs, but those payoffs come relatively infrequently.
So how about cutting off networks that are the sources of this kind of abuse? There are some *clearly* bad actors in the networking space and yeah, action does occasionally get taken against them. But these actors are generally prepared for these kinds of enforcement actions, so they are pretty hard to get rid of entirely. 'Bulletproof hosting' is one of the names these actors go by these days.
At least in our dataset, part of the problem is that the attackers are from *everywhere*, with a lot of them probably using compromised devices in people's houses, businesses, datacenters, etc. So the networks, and even device owners, are not themselves malicious and it's hard to do much without a lot of collateral damage. For example, here are the top five networks that were the sources of attacks in our dataset:
China Telecom (26.8%), China Unicom (6.1%), DigitalOcean Cloud (6.0%), Tencent Cloud (5.5%), OVH Cloud (2.9%), and the Vietnam Posts and Telecommunications Group (2.7%).
(we list a lot more in tables at the end of our paper.)
These are all large ISPs and cloud providers that, frankly, it would be pretty hard to exert much pressure against.
We are actually doing a study where we're trying to interview a variety of network and security admins about these kinds of problems, and I would say that what we're finding so far is that basically the networks of people working on stopping network abuse mirror human social networks: eg. US academic institutions generally cooperate with each other, cloud providers generally know each other, etc. There are also some formal coordination groups like CERT/CC.
So that was a pretty long answer :) but in general, yes, a lot of people work on stopping network abuse, no, that has not eliminated it, and no, it probably never will, we will always been in *some* form of the cat-and-mouse game that characterizes most Internet security work.
1
0
0
Josh Triplett
josh@joshtriplett.orgSome of the cloud providers, at least, seem like it'd be possible to work with to establish outbound-network policies like "no SSH brute-force attacks". But yeah, probably little hope playing whack-a-mole with the end-user ISPs.
0
0
0
Jim Winstead
jimw@mefi.social@ricci A side note that ties this to the recent #XZ backdoor is that it wasn’t uncovered because Andres noticed it was 500ms slower when he logged in to his machine, it was because these relentless pervasive login attempts were showing up as sshd processes chewing CPU, impacting the profiling he was doing.
1
0
0
Rob Ricci
ricci@discuss.systems@jimw Ah yeah, I forgot that it was other logins, not @AndresFreundTec 's that were chewing up the CPU: intrusion attempts considered helpful for discovering intrusion attempts? 🤷
2
0
0
Jim Winstead
jimw@mefi.social@ricci @AndresFreundTec Yeah, of all of the crazy coincidences that led him to the problem, that’s the one that captivates me the most. It’s like someone that stumbles onto a human trafficking ring because they got annoyed by too many spam calls.
0
0
0
Peter N. M. Hansteen
pitrh@mastodon.social@ricci @cloudlab @sachindhke if there is an increase in activity, my hunch is that it merely shows that the number of unixy (linux) hosts has grown over the years, the proportion actively involved is fairly stable. A quasi-recent writeup of mine with some links - https://nxdomain.no/~peter/Predicting_developments_in_real_world_conflict_from_patterns_of_failed_logins.html #SSH #security (also https://nxdomain.no/~peter/badness_enumerated_by_robots.html and links therein)
1
0
0
AndresFreundTec
AndresFreundTec@mastodon.social 0
0
0
0
0
0
Rob Ricci
ricci@discuss.systems@AndresFreundTec @jimw Interesting! I know that the backdoor won't execute the code passed to it until well into the ssh handshake, but does the symbol scanning etc. happen as soon as the connection is `accepted()`ed? In other words, if they are just connecting to the port as part of a 'normal' port scan, does that trigger the the CPU usage? Or do they have to actually start the ssh handshake?
1
0
0
AndresFreundTec
AndresFreundTec@mastodon.social@ricci @jimw The CPU usage happens during process startup. sshd forks+execs a new process for each connection (and then forks another one for privilege separation, but because it's a fork it doesn't trigger the startup overhead).
Due to that, the overhead is visible as soon as a connection is established. The only thing that happens between accept() and the fork()+execv() is enforcement of MaxStartups.
0
0
0
Jonathan Corbet
corbet
1
1
9
Peter N. M. Hansteen
pitrh@mastodon.social@ricci @cloudlab @sachindhke Thanks!
It's a collection of fairly gnarly problems there, but I think proper logs analysis from enough honeypots like mine will help us deal with several of them.
0
0
0
Genders: ♾️, 🟪⬛🟩; Soni L.
SoniEx2@chaos.social@ricci @cloudlab @sachindhke do you know if switching to ipv6-only could solve the issue?
1
0
0
Rob Ricci
ricci@discuss.systems@SoniEx2 @cloudlab @sachindhke An excellent question that I can only speculate on right now, in part because our study only covers IPv4, and in part because I expect the landscape to change, but it's hard to predict exactly how.
In the short term, switching ssh and other services to #IPv6 only will *likely* reduce the brute force attacks you see by a *lot*. Our data suggests that attackers are hitting the IPv4 space at random, which is a perfectly good strategy for the relatively dense IPv4 space, but a terrible strategy for the gigantic IPv6 space. If I were an attacker doing brute force, I'd stick to the IPv4 space that's easy and has plenty of targets.
However, let's consider more sophisticated attackers, and/or a future world where we've moved entirely to IPv6. There are lots of things you can do to cut down the scanning space. Most IPv6 space is not even allocated, so you can just skip that. You can focus on specific prefixes used by large ISPs and cloud providers to increase your hit rate. You can use information about the way some devices use MAC addresses to generate part of their public address to target popular NIC and or IoT vendors. You can keep track of live IP addresses based on observed connections (eg. scan everyone who connects to your website.) You can try to enumerate DNS domains to look for targets (most DNS servers try to prevent this, but there are all kinds of attacks on DNS). You can share lists of the live addresses you find. And these are just off the top of my head, I'm sure people have come up with plenty more already, and will find plenty more in the future.
So, will we eventually reach a point where IPv6 scanning is as effective as IPv4 scanning is today? It seems unlikely, but scanning the entire IPv4 space in minutes seemed unlikely not too long ago. So in the long term, I wouldn't bet on security that depends on IPv6 being hard to scan. I would expect that we'll all want to keep up the same strategies of using keys, blocking attackers that we detect, etc.
One thing I would expect is for the patterns to change: right now acquiring a target is easy, so attacks that just try once and move on are common. On IPv6 - both now and in the future - I'd expect that the difficulty of finding targets means that once you find one, you're going to try a *lot* more usernames and passwords on it.
0
1
0
Zack Weinberg
zwol@hackers.town
@ricci @sachindhke Nice work! Looking forward to reading this paper (when I'm not on my phone).
Does your research have anything to say about the utility of moving SSH service to a nonstandard port? I've always thought this was of little use on a server that allows only key-based access, but the xz affair has got me thinking again about preauth vulnerabilities, and maybe there's some value in being able to insta-ban anyone who sends so much as a SYN to port 22...
1
0
0
Fabian【ファビアン】🏳️🌈
fabiscafe@mstdn.social@zwol @ricci @sachindhke I switched away from port 22 and there is pretty much nothing anymore in the logs. If I remember correctly it was around 100-200 tries before (was 2019).
1
0
0
Mary Holstege
mathling@mastodon.social@fabiscafe @zwol @ricci @sachindhke
I'm on a non-standard port and I'm still seeing 1000s of attempts every day
3
0
0
Fabian【ファビアン】🏳️🌈
fabiscafe@mstdn.social@mathling @zwol @ricci @sachindhke you're probably on a bigger, more known server. It's not magic that will fix the problem. 
1
0
0
Rob Ricci
ricci@discuss.systems@mathling @fabiscafe @zwol @sachindhke It's possible that someone has scanned you, figured out what port you are running ssh on, and put it on some list - eg. check your IP address on shodan.io and see if anything interesting turns up.
0
0
0
Damien (TIG BUSINESS)
aeduna@aus.social@fabiscafe @mathling @zwol @ricci @sachindhke i actually think there are port scanners out there that build up libraries of "this ip runs ssh on this port" and they reference that.
I switched to non-standard and it was quiet for a while, but its pretty constant now.
The "block for N fails" things don't really work any more on anyone competant, they have a big network of bots, and each one works its way around only hitting you once then moving on.
0
0
0
MarkD
markd@hachyderm.io@mathling @fabiscafe @zwol @ricci @sachindhke Yep. I'm with Mary on this one. I have multiple servers running on non-standard ports and some of them still get fairly hammered (tho not as much as port 22) while others rarely get touched. It's mostly luck of the draw.
0
0
0
Fabian【ファビアン】🏳️🌈
fabiscafe@mstdn.social@suihkulokki not possible for me. Still to many places without available v6 connection
0
0
0