Jan Antoš
janantos@f.cz
Mě fascinuje ten odpor k #LLMs a #AI obecně. Ale většina těch lidí si neuvědomuje, že bez toho by neměli například strojové překlady webu v prohlížeči, voice to text pro hluché, image to text pro nevidomé, optimalizované řízení silničního provozu a hromadu jiných vychytávek. Ja konkrétně používám LLM i pro sumarizaci a šetří mi to hodně času. Mě to trochu připomíná, když lidi ničili automatizované tkalcovské stavy na počátku průmyslové revoluce.
 2
2
 0
0
 0
0
idle
idle@hlad.org@janantos
Ti lidi, co ničili stroje, nebyli ani tak proti těm strojům jako proti tomu, že najednou místo dosavadní kvalifikované práce sehnali akorát tupou otročinu za špatných podmínek a za mizerný peníze.
Ne že bych se chystala něco rozbíjet, ale tu frustraci chápu.
1
0
0
Jan Antoš
janantos@f.cz@idle a ja jsem nasadil AI a ušetřil teamu o 4 lidech celkem cca 130 hodin monotónní práce. Takze jsem v podstatě časově skoro nahradil jednoho člověka. Nastalo propouštění v tom teamu? Ne nenastalo, akorát ten čas mohou věnovat smysluplnější práci. Team mi vřele poděkoval a jsem teď jejich superstar. Ted za mnou chodí data analysti s nápady jak jim ulehčit/zefektivnit práci.
1
0
1
idle
idle@hlad.orgTak to je dobrý, to je teda nějaká činnost, která se dá snadno zkontrolovat, že je dobře? Protože to je pro mě to hlavní bolestivé místo: kontrola. Třeba když si nechám při překládání před-přeložit texty a opravuju je, tak mi to čas ušetří, ale je to mnohem náročnější na pozornost (a míň zábavný) než překládání samotné.
1
0
1
idle
idle@hlad.orgTak to jo. Já většinou narážím na věci, které buď řeší regulární výraz či jiný deterministický postup, a nebo to stejně musí procházet člověk.
2
0
0
Chao-c'
xChaos@f.cz@idle @janantos strojové překlady jsou dobrý argument, ale tam je jasné, že vidím původní text v cizím jazyce, kliknu na "přeložit" a pak je jasné, že koukám už na strojově generovaný text.
Moje výhrady se týkají rozpoznatelnosti, zda si povídám s člověkem, nebo se strojem. Je to pro mě dost zásadní. To samé např. v případě AI generované fotografie - tam to může být ještě zásadnější.
V zásadě se strojové generování obsahu zas tak dalece neliší od samotného googlení... ale zamýšlet se, jestli strojově generovaný obsah budeme rozlišovat od člověkem vytvořeného, podle mě přeci jen dává smysl. Spousta lidí třeba chce mít výtisk knihy podepsaný přímo od autora, apod.
Ve skutečnosti jsem se dnes dostal v jedné online debatě do situaci, kdy mi vyčetli nesrozumitelnost a doporučili, ať si to nechám nastylizovat od LLM. Nevím, jestli ironicky nebo neironicky... ale je to směřování, které se mi celkově nelíbí.
Proto na naší instanci např. kladu důraz na občasná osobní setkávání uživatelů, apod. Myslím, že v brzké budoucnosti se může stát, že jen lidi, které jsme někdy viděli osobně, budeme online pokládat za skutečně reálné....
1
0
1
Pavel Machek
pavel"Chat z Jezisem", napr. "OpenAI doporucuje LLM pro zdravotni informace". "O2 robot pred kterym neni uniku, a ktery skoro nefunguje".
LLM se da velmi snadno pouzit spatne, viz ruzni trollove etc. Nebo firmy ktere nabizeji "chat" a misto cloveka je tam LLM. Odporu se nedivim.
Ano, LLM je potreba na strojovy preklad. (A myslim ze proti strojovemu prekadu by nebyl velky odpor). Ano, LLM by se asi dal pouzit pro text-to-speech, ale text-to-speech se da udelat i bez LM .. a tedy i bez LLM.
Optimalizovane rizeni silnicniho provozu...?
2
0
2
Jan Antoš
janantos@f.cz@pavel AI != LLM
1. V dnešní době naprostá většina speech-to-text systému jsou neuralni sítě. Tradiční HMM/GMM už převážně byli nahrazeny NN.
2. OCR absolutně NN
3. Automatizované KYC, opět NN OCR s NN face recognition
4. Traffic control - object recognition, opět NN, například speed camera
5. Optimalizované řízení provozu - viz například Tallinn AI dynamic traffic lights pilot, nebo bus lanes monitoring AI cameras.
6. LLMs se velmi osvědčili v sumarizaci textu a Text extraction v document systémech.
7. Nejspíše nefunguje je vas čistě subjektivní názor, samozřejmě se vždy najde nějaká naprosto debilni implementace a použití, ale to platí i o tradičních statistických metodách, že?
Takze se nebavme o rychlokvaškách a černých dírách na peníze investorů, ale o technologii jako takové.
2
0
0
Pavel Machek
pavel"AI" znamena "nefunguje to na 100%".
A technologie jako takova muze byt fajn. Ale kdyz ji ruzne firmy pouzivaji blbe a/nebo neeticky, uzivatele to samozrejme vnimaji, a nevnimaji to pozitivne.
A kdyz je v nejakem oboru prilis mnoho cernych der na penize investoru, tak to hold take zanecha stopu.
0
0
1
Jan Antoš
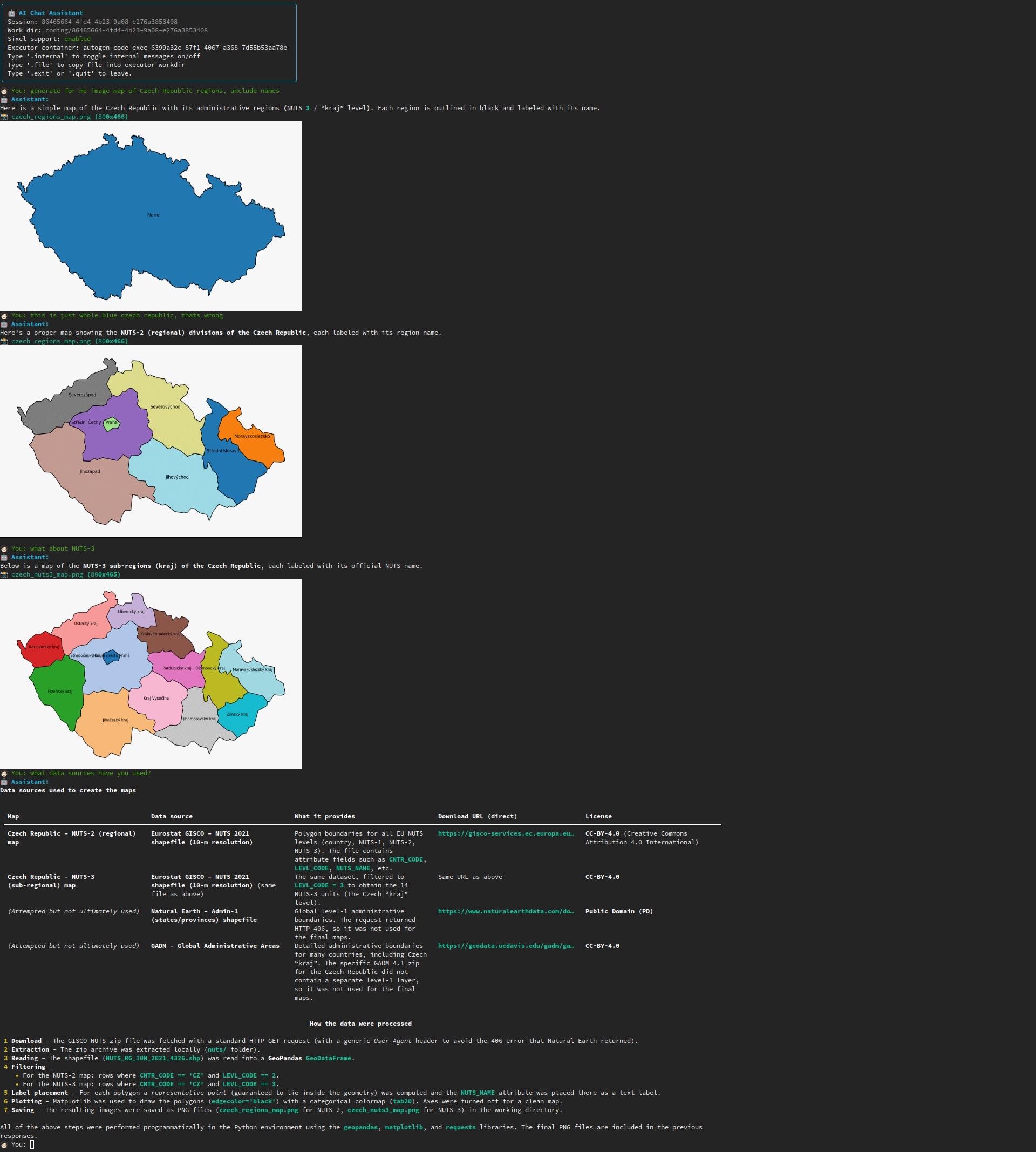
janantos@f.cz@pavel jen pro představu, nikdy by mě nenapadlo založit firmu nabízející chatbota, to ale neznamená ze jsem si nenapsal svého vlastního AI asistenta (Agentic AI), LLM (gpt-oss 120b si self-hostuji doma), chat je plně terminálová aplikace se sixel supportem, a Retrieval augmented generation. sám jsem byl celkem překvapený tak si to poradilo s poměrně vágním zadáním a jak se ti s tim popralo. Viz obrázek. Toto je jeste screenshot z předchozích verzí. Dnešní minut v podstate v pravidelných intervalech sumarizuje release notes a breaking changes několika desítek projektů.
 1
0
0
1
0
0
Pavel Machek
pavelTaky sem si hral, moje pokusy jsou na https://gitlab.com/tui/tui/-/tree/master/vosk?ref_type=heads .
Ale obavam se, ze povest "AI" mezi uzivateli to uplne nevyresi, protoze vic lidi uvidi (neetickou, otravnou) "AI asistentku O2" nebo (nefuncniho, nedodelaneho, otravneho) "AI asistenta na Zoomu" nez nase pokusy.
0
0
0
Chao-c'
xChaos@f.cz@pavel @janantos to, že tomu nerozumíme, je jen jeden aspekt. Většina lidí nerozumí ani "konvenční" informatice, takže tohle se dotýká jen určité dejme tomu stavovské hrdosti části programátorů (spíše než administrátorů), ale není to hlavní důvod.
Musíme odlišit nechuť k AI textům od nechuti k AI generovanému audiovizuálnímu obsahu, který si hraje nějak na "umění". To jsou dvě kategorie. Text je pro určitou skupinu lidí asi vážnější kategorie, pro jinou méně závažná. U toho textu je ale závažný problém to, že AI se snaží splnit zadání a když nezná to správné, tak si prostě něco vymyslí. Tohle začne být vážnější problém a povede k tomu, že přestaneme důvěřovat textům jako takovým. (Zase: tohle nebude problém pro část populace, která jim v podstatě nedůvěřovala nikdy...)
Přitom já nejsem proti AI jako takovému... dovedu si představit užitečnost machine learning nad obrovskými vzorky dat, kde si může rozeznat vzorců, které by člověka nikdy nenapadly, při aplikaci běžných statistických postupů. Užitečný je strojový překlad a do jisté míry věřím "strojovému zhuštění", "zestručnění" textu - to je něco jako snížení rozlišení u digitalizovaného obrázku, v jistém smyslu.
O co konkrétně jde je to, že nebudeme schopni rozeznat obsah, který vytvoří člověk, od obsahu, který vygeneruje AI. Což zase není až tak něco nového, protože stejně programy předvyplňovaly různé šablony, nebyli jsme schopni rozeznat fotografie od montáže ve Photoshopu, apod. Ono to v zásadě není nic, co by s náma nebylo už delší dobu... ale spíš mizí poslední záchytné body, které nám umožňovaly rozlišit, jestli interagujeme s člověkem, nebo se strojem.
V zásadě nejde o to, že bych se chtěl pouštět do nějakého zásadního odporu a filtrování, který je nemožný - ale nechci například vynakládat svoje zdroje na hostování AI generovaného obsahu. Do toho už investuje dost lidí, já do toho investovat nechci...
1
0
1
Jan Antoš
janantos@f.cz@xChaos @pavel myslim ze tady se naprosto shodneme. Me pomerne hodně ma nervy leze AI generated content na webu (možná bych si tak nějak dokázal představit AI generated rss feed), to je i pro me jako AI evangelistu čára, za kterou nejsem ochoten jít. Jak jsem už napsal výstup z AI by mel byt označen jako AI generated.
1
0
1
Chao-c'
xChaos@f.cz@janantos v tom případě nemáme mezi sebou žádný spor...
Já ani nevím, jestli takové pravidlo na instanci budu zavádět, i když v hlasování by s ním asi většina souhlasila. ponechám to nejspíš na dobrovolné bázi.
Obecně, úsilí, které jsem v životě věnoval provozování nějakého kusu Internetu, jsem chtěl věnovat obsahu vytvářenému lidmi, i kdyby šlo jen o fotky z dovolené a blbé vtípky.
Jakýkoliv strojově generovaný, tedy i AI generovaný obsah chápu v situaci, kdy jde o něco, co člověk principiálně vytvořit nemůže, apod. Ale možnost, že to bude konkurovat obsahu, který lidi vytvářejí kvůli nějakému sebevyjádření, sebeidentifikaci, sebeprezentaci, apod., mě vadí v tom smyslu, že když už tomu nemůžu zabránit, nechci k tomu aspoň přispívat...
1
0
0
Jan Antoš
janantos@f.cz@xChaos @pavel já vidim AI use case jako nástroj pomoci člověku, aby nemusel dělat něco jako práci pro cvičenou opici. A například manuálně navštěvovat desítky projektů a sumarizovat release changes/breaking changes je přesně use case kde vidím AI jako řešení. A to je přesně věc na které teď pracuji.
1
0
0