Conversation
Greg K-H
gregkh
There's been a long nerd-sniping thread recently here from @monsieuricon where email message-ids were being discussed and generated in semi-interesting ways that ended up detouring me and @brauner into writing up competing python vs. perl scripts to get `git send-email` to properly use our new bespoke message ids:
https://social.kernel.org/notice/AU5IphRPUsQvvkx732
But why does any of this matter? As most everyone knows, Linux kernel development happens through email, and the Message-Id of an email is a unique identifier that is used to track messages in our patch handling tools and archives (see https://lore.kernel.org for the archives.) By crafting shorter-but-still-unique message ids it's easier to reference those messages in other places, and using words is just prettier overall than random UUID values (https://i.redd.it/64gl4t9s52ra1.jpg for an example)
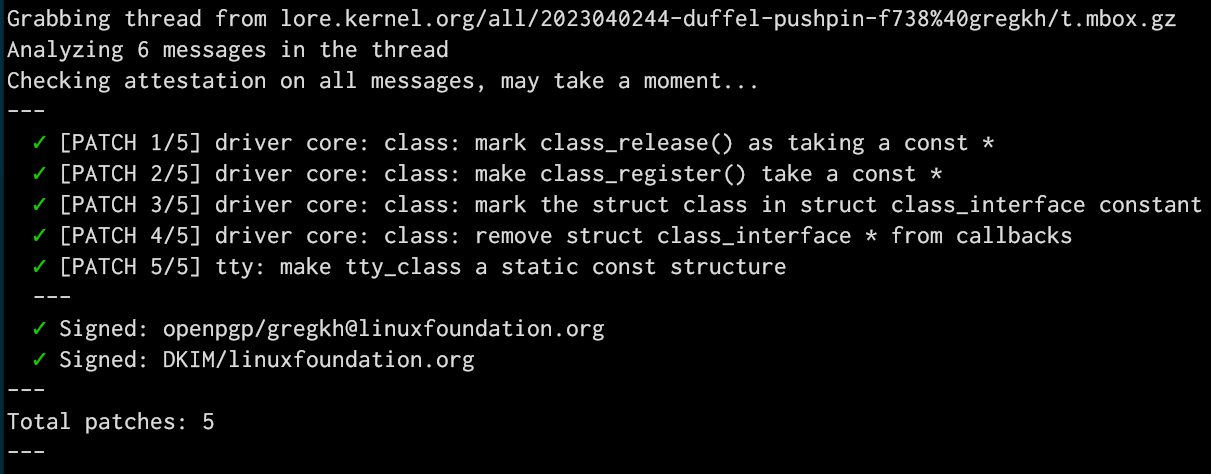
Bonus to all of this is that people don't realize that most of the patches we send out are actually signed and can be validated as coming from the person that sent them. The tool we use for that looks at the body of the email, and a small subset of the Header tags in the email. By providing to the tool our custom Message-Id, that adds yet another portion of the email that is now able to be signed and validated, providing a tiny bit more security overall in the patch submission processes (very very tiny, I know, but it's real, as I found out when I submitted a patch with a broken message-id from what was signed and our tools caught it.)
Anyway, all of that is a long way of showing off a tiny core change to the kernel that allows some core structures to be moved to read-only memory that I've been working on for a few months now. Here's the last portion of that work being sucked off of the email archives and validated as coming from me:
https://social.kernel.org/notice/AU5IphRPUsQvvkx732
But why does any of this matter? As most everyone knows, Linux kernel development happens through email, and the Message-Id of an email is a unique identifier that is used to track messages in our patch handling tools and archives (see https://lore.kernel.org for the archives.) By crafting shorter-but-still-unique message ids it's easier to reference those messages in other places, and using words is just prettier overall than random UUID values (https://i.redd.it/64gl4t9s52ra1.jpg for an example)
{kind=link}
Bonus to all of this is that people don't realize that most of the patches we send out are actually signed and can be validated as coming from the person that sent them. The tool we use for that looks at the body of the email, and a small subset of the Header tags in the email. By providing to the tool our custom Message-Id, that adds yet another portion of the email that is now able to be signed and validated, providing a tiny bit more security overall in the patch submission processes (very very tiny, I know, but it's real, as I found out when I submitted a patch with a broken message-id from what was signed and our tools caught it.)
Anyway, all of that is a long way of showing off a tiny core change to the kernel that allows some core structures to be moved to read-only memory that I've been working on for a few months now. Here's the last portion of that work being sucked off of the email archives and validated as coming from me:
 0
0
 14
14
 28
28