
Jarkko Sakkinen
jarkko 1
1
 0
0
 0
0
Jarkko Sakkinen
jarkko1. A/S/E subkeys inside Yubikey.
2. C (#certificate) key as TPM2 ASN.1 blob.
The C key can be tied a to single chip during its creation. If someone gets a copy it is useless without that exact chip.
For the sake of defense in depth, a maintainer would keep that exact blob still in USB stick.
This scheme would be pretty airtight as even certification creation while the machine is online, would have quite low risks. E.g. if the ASN.1 blob is stolen while online, the key is useless by itself.
So in the context of #Linux #kernel #PGP #maintainer #guide this would make the whole process way more relaxed and convenient with the help of TPM2 chip.
How we deal with subkeys that part is smooth but there's still room for improving The Maintainer Experience when dealing with your Certification key :-)
I will work on user space shenanigans for this maintainer flow upgrade after this patch set is finished: https://lore.kernel.org/linux-integrity/20240528210823.28798-1-jarkko@kernel.org/T/#t. I.e. find good route for gnupg to access the TPM2 (RSA4096/Curve25519) key, which is imported OpenPGP cert key...
1
1
0
repeated
nixCraft 🐧
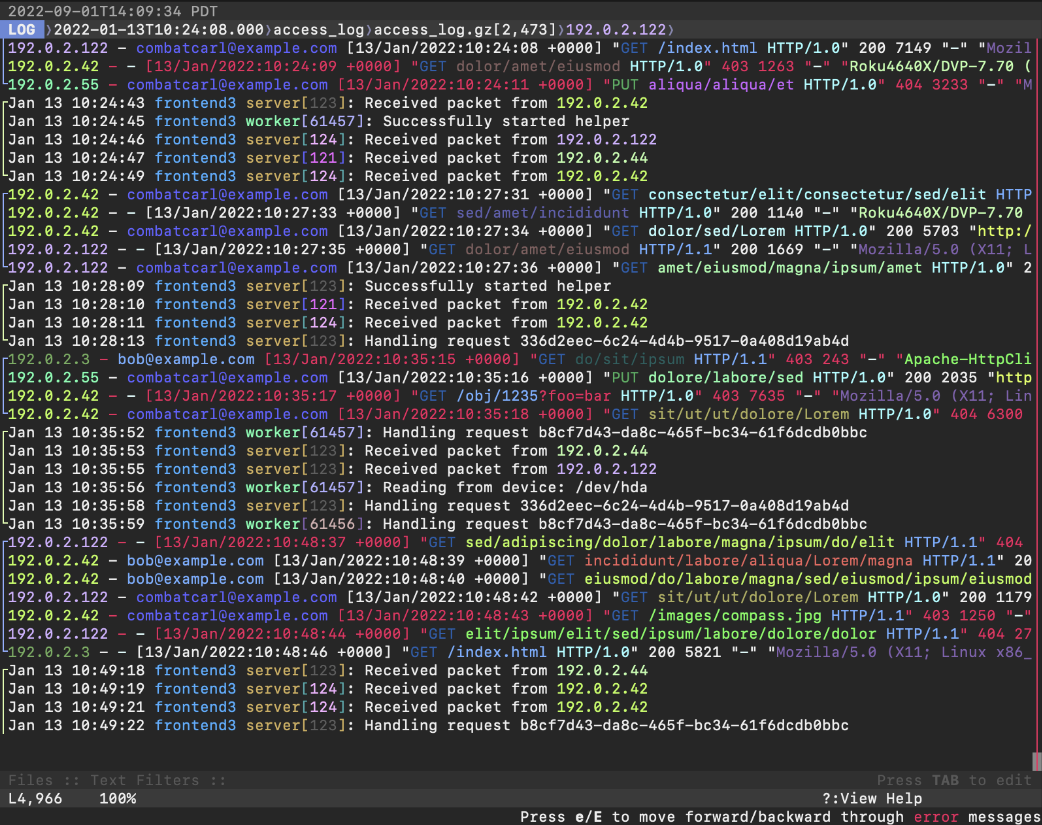
nixCraft@mastodon.sociallnav is a terminal-based log file viewer (TUI) for #Linux, #FreeBSD, #macOS, and other #Unix like systems. It combines the functionality of tools like tail, grep, awk, sed, and cat into a single interface. It also allows you to run SQL queries against your log files to build reports and offers basic support for Linux containers like Docker. lnav – Awesome terminal log file viewer https://www.cyberciti.biz/open-source/lnav-linux-unix-ncurses-terminal-log-file-viewer/
 2
5
1
2
5
1
Jarkko Sakkinen
jarkkoMy question would be this why you want to do anything to address the (context-dependent) conclusion that “Python is slow”? ;-)
How I would address [1] with any Python3 dot release would be:
- LATENCY: Manual driver/controller in the app for
gc.*for the sake of predictability in timing. Run it when your app is idling. Do not run it at the hot spots. - BANDWIDTH: Use a freaking C-library for the payload processing. By practical means all of them have Python bindings.
[1] https://thenewstack.io/why-python-is-so-slow-and-what-is-being-done-about-it/
0
1
0
Jarkko Sakkinen
jarkkoI've been slandering Rust community for making forks of every possible thing but I do think I'm in different grounds here ;-)
But in this case I disagree with core ideas of the architecture, cannot do the tasks that I need to now as an end user, and I have my own code base starting from epoch.
So literally I will never get the tool that I need myself, if I do not create a competing platform. Now I got first essential pieces what I needed in 48h. Thus, I think I'm in legit grounds with this and doing the right thing.
0
0
0
Jarkko Sakkinen
jarkko@hunger And there’s one huge contradiction between how I see the stack should work in the user space and how TCG sees it.
I did not believe in TrouSerS and neither do I believe in TSS2. User space arbitrator is just a bad idea as far as I’m concerned. And tpm-rs crate’s docs already have hints that they want to do something similar at very least.
I think a single chip can at most exactly two tasks:
- Managing persistent and transient with /dev/tpm0
- Managing transient only bu per open file with /dev/tpmrm0.
Anything that tries to scale up from this with a crazy and complex daemon is just totally misguided in architecture [1]. Never try to scale anything beyond what it has capabilities for.
For multiplex, e.g. for guests or containers, a decent vTPM implementation (posssibly attestated by the hardware chip, and thus doing arbitration in different layer or by the means of SGX/TDX/SNP) would be so much better approach, despite having challenges of its own.
It is something that one can understand is within limits of scalability of a chip (literally I mean think of more complex task like primary key generation).
[1] https://www.joelonsoftware.com/2001/04/21/dont-let-architecture-astronauts-scare-you/
1
0
0
repeated
K. Ryabitsev-Prime 🍁
monsieuriconhttps://lore.kernel.org/tools/20240614-flashy-inquisitive-beaver-ddcfea@lemur/T/#u
3
10
22
Jarkko Sakkinen
jarkko@hunger I have also somewhat clear milestone deriving from a kernel patch set: https://lore.kernel.org/linux-integrity/20240528210823.28798-1-jarkko@kernel.org/
For v8, one of the goals is to have the smoke testing transcripts described in tpm2-cli.
Main gist of upcoming changes for my crate are scoped in the this:
tpm2_createprimary --hierarchy o -G rsa2048 -c owner.txt
tpm2_evictcontrol -c owner.txt 0x81000001
openssl genrsa -out private.pem 2048
tpm2_import -C 0x81000001 -G rsa -i private.pem -u key.pub -r key.priv
tpm2_encodeobject -C 0x81000001 -u key.pub -r key.priv -o key.priv.pem
openssl asn1parse -inform pem -in key.priv.pem -noout -out key.priv.der
[and similar for ECDSA]
In my project tpm2_call has the protocol layer and zero OS specific shenangians, i.e. it is ultra-portable.
However, in tpm2-cli I can just add a command that does the equivalent flow using openssl and asn1 crates. Generally the winds and stream in this project go in a way that I let shit grow in tpm2-cli and abstract away stuff that is agnostic and mature enough to tpm2_call. This way abstraction formalize by evolution and stimulus and not by top-down design…
1
0
0
Jarkko Sakkinen
jarkko@hunger yep, so for me it is somewhat is easy choice because I’m the main consumer of my own product.
For instance the first pieces of functionality are response code to (spec) mnemonic decoding and object enumeration. I wrote those only because that will free from having to use tpm2_rc_decode and tpm2_getcap for this again.
Consortium projects can have sometimes issues that there is bunch of people who do not actually use it every day in their tool set. I.e. ‘’let’s do something ugly that covers our spec” type of acting ;-)
The second problem is that often in such projects moving changes to upstream can take ages because nobody cares that much. So I can either choose:
- Have arguments, frustration and anger at Github issues.
- Write meaningful functionality that I need and use straight out of the bat.
All I did in 48h improved my kernel flow at instant. That is at least measurable benefit. Doing for myself, not for users ;-)
1
0
0
Jarkko Sakkinen
jarkkoClosed my tpm-rs bug because I do not want to contribute to that project: https://github.com/tpm-rs/tpm-rs/issues/71#issuecomment-2171360982
Why? I think mine is better or will grow so much better than this. It is more idiomatic #Rust, and generally less layered and more lean and mean ;-)
I will review merge requests for mine tho, on the basis of common sense and code quality tho: https://gitlab.com/jarkkojs/tpm2_library/-/issues
1
1
0
Jarkko Sakkinen
jarkko
0
0
0
Jarkko Sakkinen
jarkko@cgwalters @fale BTW, is the Fedora version up to date or would it be more advisable at this point to build from upstream (0.1.11)? Or is there a more bleeding edge copr for this work?
I have personal interest for this because to this day I’ve used libvirt for development environments and qemu-system-* for more automated QA [1]. For the former use case this might be my entry to popular “development containers” ;-) So I might be even willing to fix some issues along the way, if I encounter any.
I’m more of a “allow list” than a “deny list” type of person, and thus Linux containers have felt to me quite bad to this day, to be honest.
<personal-and-extremely-subjective-opinion> Docker is a great example of a successful duct tape product to fix something broken to appear as unbroken ;-) Market was formed by bad design decisions in kernel (emphasis on subjectivity of this opinion) [2]. </personal-and-extremely-subjective-opinion>
[1] https://gitlab.com/jarkkojs/linux-tpmdd-test [2] Mainly speaking about the “evil net of namespaces”, which is a mess. I think Cgroups in its second iteration is quite good actually for what it does.
0
0
0
Jarkko Sakkinen
jarkkoI should have put my words better but does it use like same tricks and ideas still, like e.g. using DAX as a tool to bypass page cache of the guest kernel? Does this have some new ideas in the nitty gritty details level? Obviously heavy use of virtio like anything in this part-container/part-vm space...
2
0
0
Jarkko Sakkinen
jarkko
0
0
0

Jarkko Sakkinen
jarkkoTPM2 command encoding with #bincode and #serde:
let options = DefaultOptions::new()
.with_fixint_encoding()
.with_big_endian();
buf.extend(&options.serialize(&(Tag::NoSessions as u16)).unwrap());
buf.extend(&options.serialize(&22_u32).unwrap());
buf.extend(
&options
.serialize(&(CommandCode::GetCapability as u32))
.unwrap(),
);
buf.extend(&options.serialize(&(Capability::Handles as u32)).unwrap());
buf.extend(&options.serialize(&HR_PERSISTENT).unwrap());
buf.extend(&options.serialize(&1_u32).unwrap());