Jarkko Sakkinen
jarkko
Great now I think I have solid base traits in place i.e., TpmCast, TpmCastMut, TpmHasCast and TpmHasCastMut:
I also relaxed the contribution guidelines just a little bit:
//! * `alloc` is disallowed.
//! * Dependencies are disallowed.
//! * Developer dependencies are disallowed.
-//! * Panics are disallowed.
+//! * Panics are allowed disallowed by default, except concrete type casts in
+//! `TpmCast::as_slice` is allowed to use `unwrap` as long as
+//! `TpmCast::from_slice` meets the documented contract.
 0
0
 0
0
 0
0
Jarkko Sakkinen
jarkkoWhat would be a simple stochastis model that I could apply to my serial link emulator to add "realistic line noise", and don't have climb mountains to implement the algorithm?
0
0
0
Jarkko Sakkinen
jarkkoModern IDEs feel like ransomware. They completely destroy the screen when there's like one punctation mark missing or something and only thing that auto-complete accomplishes for me is the lost focus on task.
I tried in Sublime Text with Copilot only because Microsoft provides me a free pro license for it and it was even worse than normal autocomplete given it's wrong and fallible suggestions that completely destroy focus. I just wanted to see what it is like and it was piece of shit tbh.
Rust macros are actually a bit like "autocomplete all my objects with traits" type of tool where you write a recipe on how to auto-complete.
0
0
1
Jarkko Sakkinen
jarkkohttps://git.kernel.org/pub/scm/linux/kernel/git/jarkko/tpm2-protocol.git/commit/?id=03ffb2a9fc5026dbbedd2e1bbdf52bb3cc7dc564
@Dr_Emann, and yep:
- ($ty:ty, $variant:ident) => {
+ ($ty:ident, $variant:ident) => {
EDIT: extended further to lists (and commit ID above updated) as TpmList was a pretty good test case for the trait definition itself. Luckily I had used PhantomData a few times when contributing to Enarx few years ago so I was able to make this stretch :-) Now I have like the baseline for doing zercopy in place.
1
0
0
Jarkko Sakkinen
jarkkoThis starts to “feel right” when it comes to “zerocopy”:
pub trait TpmCast<'a>: Sized {
fn cast(slice: &'a [u8]) -> TpmResult<Self>;
fn as_slice(&self) -> &'a [u8];
}
And pretty analogus to pre-existing TpmBuild and TpmParse i.e., they provide clone semantics and this is like hierarchical pointer.
It’s pretty easy to squeeze in because I only really have to edit macros for the most part. I have already basic types, and buffers and lists will follow the same patterns.
0
0
0
Jarkko Sakkinen
jarkkoAnother more fun Rust related activity is figuring out how to nail batch file transfer test planning with emulated serial port that throttles the speed to a target BPS (in future also should have also signal noise emulation):
const ADJECTIVES: &[&str] = &["Quiet", "Loud", "Fast", "Slow", "Bright", "Dark"];
const NOUNS: &[&str] = &["One", "Two", "Three", "Four", "Five,", "Six"];
const EXTENSIONS: &[&str] = &["dat", "BIN", "log", "TMP", "txt"];
struct MockPort<R: Read, W: Write> {
r: R,
w: W,
bits_per_second: u32,
next_byte_due: Instant,
}
It generates 10 pseudorandom filenames and 100 KiB payloads.
0
0
0
Jarkko Sakkinen
jarkkoJust solved a Rust sudoku for the next version of tpm2-protocol
I think this is quite clever trick to surpass some of the limitation of syntax tree macros:
macro_rules! tpm_integer {
($ty:ty) => {
pub mod $ty {
#[derive(Clone, Copy, Debug)]
pub struct TpmView<'a> {
pub slice: &'a [u8],
}
}
};
}
Further, TpmView implements a trait called TpmView. This circulates around limitation that type cannot be used to name things in syntax tree macros.
Otherwise, unless moving into procedural macros, I’d end up ugly declarations along the lines of:
tpm_integer!(u8, TpmViewU8, Unsigned);
tpm_integer!(i8, TpmViewI8, Signed);
tpm_integer!(u16, TpmViewU16, Unsigned);
tpm_integer!(i32, TpmViewI32, Signed);
tpm_integer!(u32, TpmViewU32, Unsigned);
tpm_integer!(u64, TpmViewU64, Unsigned);
Transparency has been the single biggest blocker in moving forward with zerocopy parser and this sort of “nails it”.
EDIT
I was wrong in that you could type as module name. However, the trick does still resolve the name coflict with the original type and view type. The minor inconvience of having to repeat it twice is totally acceptable vs having to manually name stuff:
tpm_integer!(u8, u8, Unsigned);
tpm_integer!(i8, i8, Signed);
tpm_integer!(u16, u16, Unsigned);
tpm_integer!(i32, i32, Signed);
tpm_integer!(u32, u32, Unsigned);
tpm_integer!(u64, u64, Unsigned);
This is absolutely sustainable for me :-) I.e. second parameter is name of the module.
Here’s a working proof of concept: https://git.kernel.org/pub/scm/linux/kernel/git/jarkko/tpm2-protocol.git/commit/?h=zerocopy&id=42f61d9d85e17f784f71c8ac64ee6adbb7171997
1
1
0
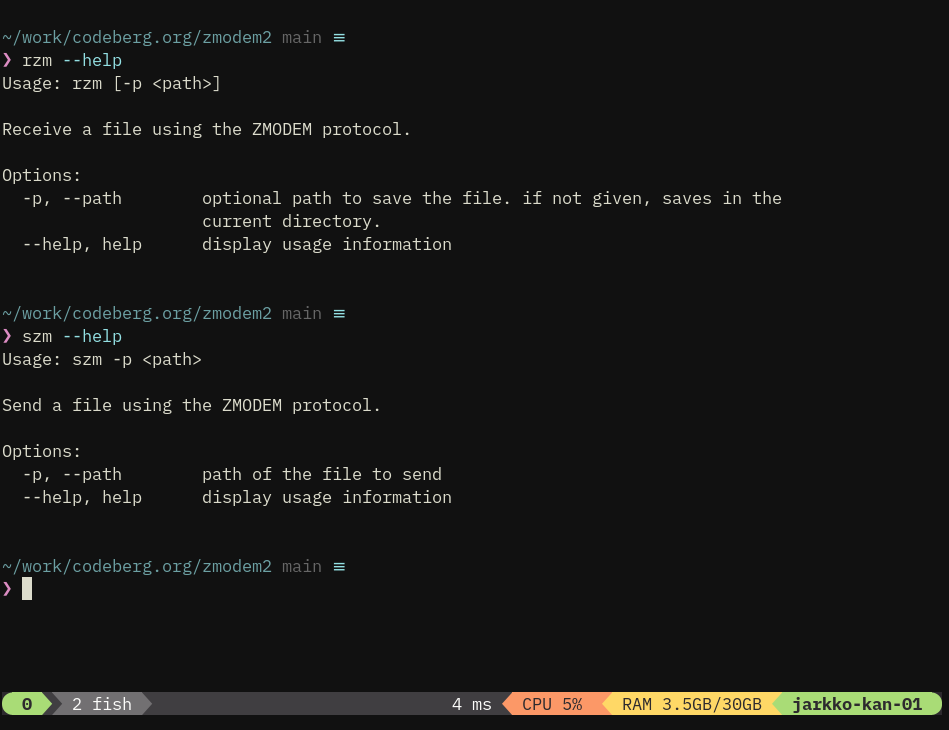
Jarkko Sakkinen
jarkkoJust like tpm2-protcol, this is a mailing list project and will be hosted at git.kernel.org.
'tpm2-policy' provides an expressive language for policies and can additionally "open code" input expressions e.g., set actual values for PCRs (if they are unspecified and digest is composed it queries them from TPM).
It can compose digests both via means of TPM2_Policy* command but in addition is capable for software composition (not yet landed tho but coming soon ;-))
The big picture design principle in this crate is, just like in tpm2-protocol, that it scales both to client use, and at the same time software composition engine is capable of empowering TPM emulator or even a real chip.
#linux #rust #tpm
0
0
1
Jarkko Sakkinen
jarkko0176 Success 80010000002000000000800200000010bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
017E TrailingData 800100000038000000000000000100000000000000010020aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaadeadbeef
0144 NotDiscriminant("TpmSt", Unsigned(0xffff)) ffff0000000a00000000
0176 Success 80010000003000000000030000000020ab967bc21b9c90096051d1e0f0dbfb29fc27258b03705fbc0c40aaaac88ed5e5
This also helps to better understand whether the pre-existing error codes make sense, how they should be modified, what should be added/removed etc. in the future versions of this crate.
1
0
1
Jarkko Sakkinen
jarkko❯ sudo target/debug/tpm2sh policy "pcr(sha256:0,7)"
pcr(sha256:0,7, 9c367f8c268d51ced151a664d88e37e74fcd84485eff8ff9bc26d22aa9091020)
With --compose flag it creates the policy digest.
0
0
1
Jarkko Sakkinen
jarkkoIt's more like UI problem than a technical problem. A great cli is such that you can put it powerpoint sheet and everyone will get it down to reconfiguring your computers.
#tpm #rust #linux
0
1
1
Jarkko Sakkinen
jarkkoMigrated few more tests to data-driven format and renamed the original test tool as 'adhoc.rs' for tests that don't fit to the data-driven framework (yet).
I think this will cage the implementation right way and over time the factor to break it will grow...
0
0
0
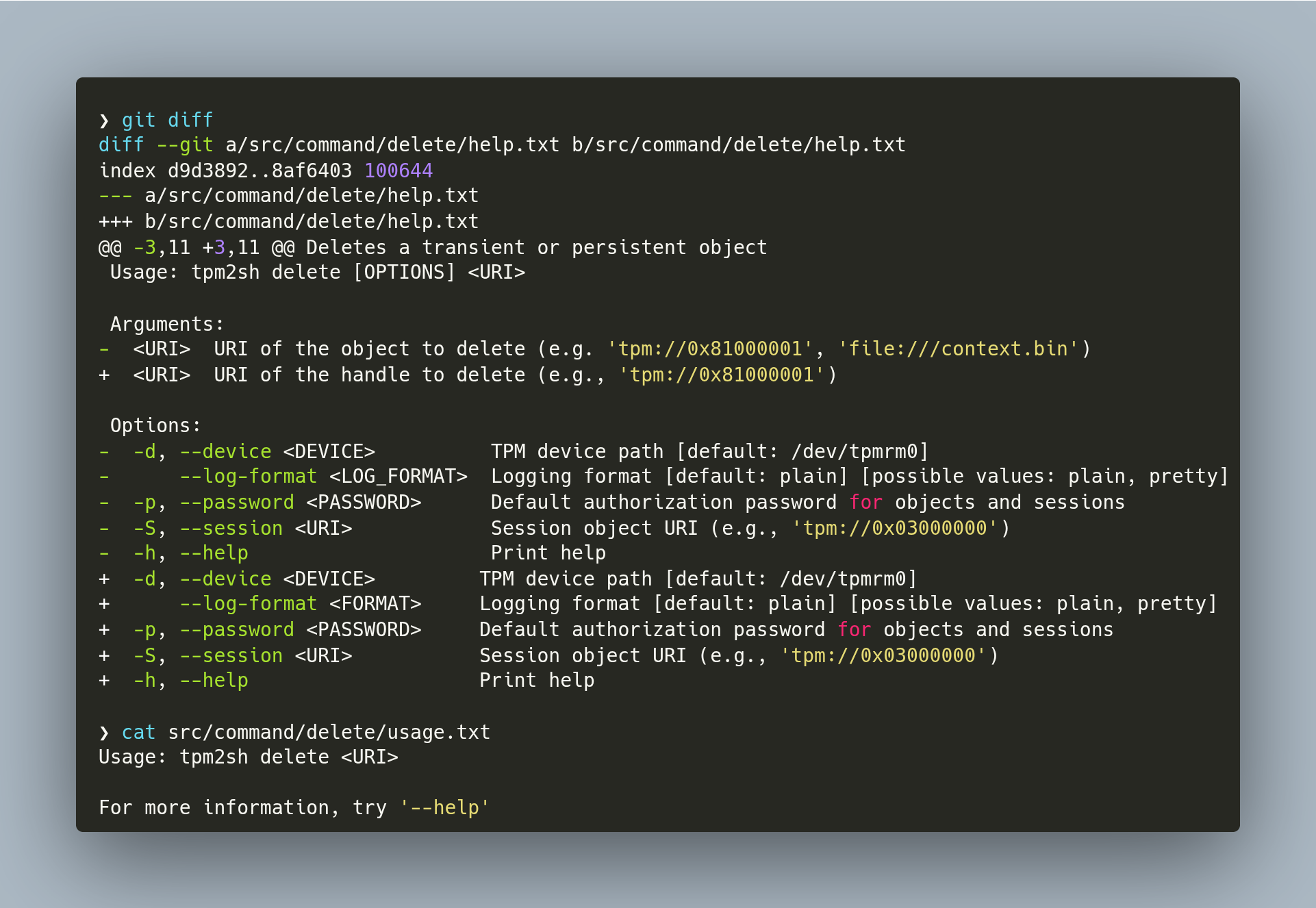
Jarkko Sakkinen
jarkko- Text files are more readable than code generation (unless you are a compiler).
- Text files has factors better outreach than code generation.
- Text files are non-executable read-only data.
- A bug in a static text file is a typo. Typo is a distraction for sure, but it does not radiate software bugs.
- The factor it simplifies command argument processing is much heavier than some minor redundancy that using text files introduces.
- Text files can be read without building a project.
#rust #clap #lexopt
 1
2
2
1
2
2
Jarkko Sakkinen
jarkkoZerocopy will be easy to implement now that I’ve found out how it is done by experimenting with basic types.
Memory requirements are relaxed as in:
- Before (0.10.x): stack is required for the artifact
- After (0.11.x): a CPU with registers will do for the memory, and read-only address for the input data.
70-80% of code base will be re-usable and remaining 20% is rewriting macros, tweaking a few call sites and creating a few new traits for macro consumption.
Despite 0.10.x having clone semantics, it is the correct traversal that is the hard problem here and it needs to be solved only once that data can be used to inject slice markers to exactly correct locations. This is why also parsing or building process nees no extra memory other than CPU cores registers.
The number lines in implementation will with higher odds go down rather than up. Looking pretty good…
0
0
3
Jarkko Sakkinen
jarkkoI'm specifically not interested on "how to program proc macros tutorial". At this point more about "geometry" and how they link and in essence all bin related info.
#rust #cargo #macros
3
0
2
Jarkko Sakkinen
jarkkoLast fix: https://github.com/puavo-org/tpm2sh/commit/3627530516fdcc8739b3c7aea6fab6a136201bfa
It's a bidirectional test where both the client and the emulator are based on tpm2-protocol. The other side sends commands and parses responses, and the other side send responses and parses commands.
Given the fair amount of software crypto involved to perform any possible bidirectional handshake it is shows off pretty well how robust the implementation is.
#rust #tpm #linux
 0
1
2
0
1
2
Jarkko Sakkinen
jarkko❯ sudo target/debug/tpm2sh algorithms
ecc:bn-p256:sha256
ecc:nist-p256:sha256
keyedhash:sha256
rsa:2048:sha256
it queries the hardware correctly and for RSA it also runs TPM2_TestParms to verify the bit sizes. it was surprsingly hard to get this right but i'd guess this might be even most accurate tool on doing this task (not because it is great but because available software sucks).
0
0
0
Jarkko Sakkinen
jarkkoThe problem I run every single time with clap is how hard it is to control if you actually want to control in detail.
Now I found the ultimate compromise for my situation:
1. I pre-rendered from clap usage and help to usage.txt and help.txt for each subcommand.
2. I changed my subcommands as directories. E.g., from "create-primary.rs" to "create-primary/mod.rs".
3. I deployed the text files to associated directories.
4. Finally I migrated parsing back lexopt.
Intial commit:
59 files changed, 538 insertions(+), 521 deletions(-)
Not too bad. WIth only parsing is just super complicated tool to do that task, or more complicated than necessary, and lexopt adds visibility to code paths so it is overall much more maintainable :-)
Also few redundant edits every once in a while to two txt files per subcommand is IMHO much more maintainable than adjusting generation from the source code.
1
0
0