Thorsten Leemhuis (acct. 1/4)
kernellogger@fosstodon.org
I fully understand why #Linux mainline developers do not have to care about stable #kernel maintenance (IOW: backporting to earlier, still supported series) at all.
And I'm mostly fine with it. But I think it's wrong when it comes to recent mainline regressions that bother users.
Especially when they cause severe damage like disk corruption (as seen by multiple reporters), as it this case:
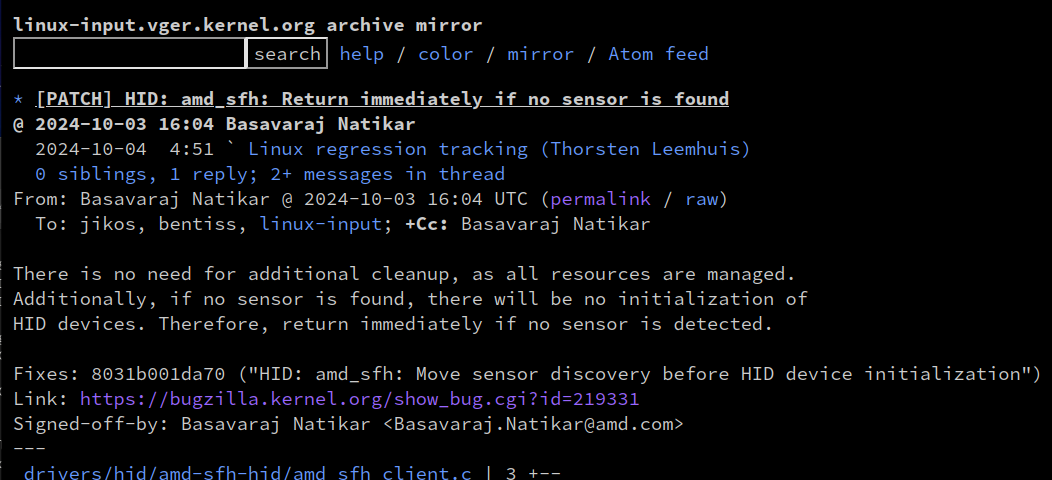
https://lore.kernel.org/all/20241003160454.3017229-1-Basavaraj.Natikar@amd.com/
Backstory: https://bugzilla.kernel.org/show_bug.cgi?id=219331 & https://lore.kernel.org/all/90f6ee64-df5e-43b2-ad04-fa3a35efc1d5@leemhuis.info/
 4
4
 1
1
 0
0
@kernellogger This is why I learned to value stability above all else on Linux over the years.
1
0
0
Thorsten Leemhuis (acct. 1/4)
kernellogger@fosstodon.orgI think we should stop using the word "stability" when it comes to Software.
* Some people read it as "don't change anything, unless there is a damn strong reason".
* Some people read it as "changes are fine, as long as everything works reliable and does not force me to do any work (like adjusting configuration files)".
* Most people think of different points somewhere in between those two.
That leads to people talking past each other.
1
0
1
penguin42
penguin42@mastodon.org.uk@kernellogger Do you have anything watching rates of reports on different CPU types? It was surprising that turned out as AMD until the bisect pointed the finger.
1
0
0
Thorsten Leemhuis (acct. 1/4)
kernellogger@fosstodon.orgNope. 🙁
Hopefully sooner or later someone will first revive/rewrite kerneloops[1] and afterwards makes things like that possible, too.
0
0
0
Thorsten Leemhuis (acct. 1/4)
kernellogger@fosstodon.org2/ BTW, if a kernel developer tells you something like "looks like the crash is not related to my change"[1], try to validate that statement and object if needed.
In this particular case the problem then most likely would have been noticed and fixed more that two months ago!
I partly blame myself that it took so long to get this fixed (which afaics would have avoided a lot of trouble for some people!), as I should have told the reporter back then to do the above.
[1] https://lore.kernel.org/all/da9ccae0-504a-48d3-ade5-a16e53b4a9b5@amd.com/
0
0
0
Jens Axboe
axboe@fosstodon.org@kernellogger IMHO maintainers very much need to (and should) care about stable! It's what people run, they don't run your development tree or the pristine new release from Linus. It's what distros rely on. Maintainers saying they don't care about stable is lazy and irresponsible.
2
2
1
Oleksandr Natalenko, MSE 
oleksandr@natalenko.name

@axboe @kernellogger I run Linus releases only exactly because I'm fed up with the "stable" stability.
1
0
2
Jens Axboe
axboe@fosstodon.org@oleksandr @kernellogger probably these two problems go hand in hand. If maintainers took better care of stable, this would not be an issue.
1
0
0
3
0
1
I think it's a little unfair/silly to imagine that enterprise distros are choosing to filter stable commits because of some conception that maintainers are just 'not paying enough attention' to it.
Stable's notorious for being anything but.
Having spent the last 3 days working flat out on fixing a regression as a non-maintainer let's say I can also sympathise with those maintainers who get fingers wagged at them for not somehow ensuring autosel is done right somehow.
2
1
1
Thorsten Leemhuis (acct. 1/4)
kernellogger@fosstodon.org@ljs: reminder: autosel and the script that quickly backports nearly everything that contains a Fixes: tag are two different things. And I think the former is not much of a problem these days due to some adjustments Sasha did -- but that is just a feeling, I have no stats to back that up.
2
0
0
0
0
1
Jens Axboe
axboe@fosstodon.org@vbabka @oleksandr @kernellogger you can just do that if you want. I just watch the queue and complain if something should not get auto picked. Either way works, and I rarely see things that should not get picked.
0
0
0
Think it's a bit easy to dismiss this as 'oh well you don't care' or something, whereas it seems to me the opposite is true - clearly some stuff in stable isn't so stable, and some things are not so easy to ensure don't get included.
Not every maintainer is as nice as they seem or don't seem, and giving a shit levels vary I'm sure, but feels very lazy to just say 'oh yeah that's maintainers being crap'.
Yeah no, I think there's more to it than that tbh.
2
1
1
0
0
1
Jens Axboe
axboe@fosstodon.org@ljs @oleksandr @kernellogger @vbabka There's no one true way, and I definitely don't care if maintainers say "don't include us in stable!" if it means that they handle it themselves and send whatever needs to go into stable to stable. What I find problematic is autosel + maintainers ignoring it, and that's clearly an autosel issue. I think it does more good than harm, but it definitely picks up patches it should not because dependencies aren't understood.
2
0
3
Jens Axboe
axboe@fosstodon.org@ljs @oleksandr @kernellogger @vbabka auto-select of patches should probably be a subsystem opt-in type of deal, rather than a default thing because of that.
The main issue here is saying stable is, well, unstable. If that's the case, then either maintainers messed up, or the process needs improving (or both). There are bugs in everything, and we need stable point releases. That part is fact. Hence we need to make it work.
1
0
2
My point is that on process - Greg controls how it's done ultimately, it's not really a democracy.
But it's easy to whine about these things and better to take action where possible at least.
For me it should be more in the control of the maintainers and the responsibility of all contributors. My objection is to any form of automated patch selection, you may not encounter many that are problematic but I'm sure it's something that varies subsystem to subsystem.
Part of it is education, but that's part of what a maintainer should do 'hey this fix relates to a change in a released kernel that should get backported to stable'.
But when you actually type that out, in 2024, you do think 'fuck me this should be automated' and again it comes back to process and how _so much_ is still manual and down to whatever subsystem maintainers want to do.
0
0
2
2
2
2
Pavel Machek
pavel
1
0
2
Jens Axboe
axboe@fosstodon.org@pavel @oleksandr @kernellogger @ljs @vbabka checking it is not necessarily easy. It may look fine and apply fine, but it depends on behavior introduced by a patch that isn't referenced at all, and which may have gone in in an earlier release. So I don't think blaming Sasha is fair, there's just no way anyone can make a 100% safe call on a patch across all subsystems in the kernel.
Maybe autosel should be emailed out, and depend on the maintainer(s) acking it to actually get included.
1
0
2
Pavel Machek
pavel
1
0
1
Jens Axboe
axboe@fosstodon.org@pavel @kernellogger Of course they care about stable, implying otherwise is nonsense. You may disagree with how they do that work, but that's a different argument.
1
0
0
Greg K-H
gregkhAlso remember that we still have areas of the kernel where subsystem maintainers and developers refuse to add any cc: stable tags, or anything else to give us a hint as to what should be backported, which is why AUTOSEL was created in the first place.
Heck, AUTOSEL catches things _I_ missed for my subsystems and forgot to tag for stable, I want it enabled for my subsystems for that reason alone. A quick glance once a week at what patches I was cc:ed on to verify they were correct is a trivial thing overall.
And as always, if you do NOT want your subsystem to be picked up for either "Fixes:" or AUTOSEL work, just let us know and we will instantly add you to our ignore list as seen here: https://git.kernel.org/pub/scm/linux/kernel/git/stable/stable-queue.git/tree/ignore_list
3
2
8
It feels like a horrible process fail but that part is not your fault more so how the hell do you get consistent handling of this with so many subsystems using mail and working independently...
0
0
1
Oleksandr Natalenko, MSE
oleksandr@natalenko.name
@gregkh @axboe @kernellogger @ljs @vbabka Two maintainers and a script cannot be smarter than ten other maintainers.
1
0
1
1
0
0
Oleksandr Natalenko, MSE
oleksandr@natalenko.name
@ljs @axboe @kernellogger @gregkh @vbabka Don't call it "stable" then?
1
0
0
I mean yeah both options are crap (imo) seems like a process/people thing of how do you get these subsystems to behave... Linus not taking patches until they behave?
I mean yeah I agree it maybe isn't as stable as you would like. But it is at least trying...
1
0
0
Oleksandr Natalenko, MSE
oleksandr@natalenko.name
@ljs @axboe @kernellogger @gregkh @vbabka Both are unstable. And yes, if you are doing things other people should do, those people will not start doing things themselves because why would they. Same with children.
0
0
1
Qais Yousef
qyousef@mastodon.social@gregkh @oleksandr @axboe @kernellogger @ljs @vbabka from my perspective, certainly not enough patches are being backported to stable which makes quality a real issue for stable kernels. Products can't move to the latest and greatest mainline easily. Most people who hit bugs don't end up reporting them. Assuming it is an obvious bug. Performance and power regressions are harder to quantify for example. Stable kernels are what real end users are on after all, not mainline kernel
1
1
1
sj
sjAgain, we shouldn't be fully convinced about the current status since we have much room to improve. I just wanted to say the current status is not really completely broken, and appreciate people including the maintainers and people proposing improvements.
1
0
4
And I (drunkenly) couldn't really argue back about it.
I did ask them for a google pixel 9 pro fold since the guard page stuff will help them out, and basically they refused and I've had to buy one myself.
Tragic!
1
0
2
0
0
2
Pavel Machek
pavel
0
0
2
Pavel Machek
pavel
0
0
1